Steampipe Stripe SQL alternative
Steampipe is an Golang based open source CLI tool that lets you query remote API's with SQL (Postgres dialect).
It is aimed at cloud API's such as those used with AWS to provision managed services.
How Steampipe works
Steampipe consists of:
-
- CLI
- Wraps the Postgres server.
- One shot: Allows passing a query on the CLI and receiving a response.
- This boots a Postgres server, runs the query, and then stops it afterwards.
- Server: The CLI also has a "server mode" to keep the Postgres SQL server running. Any process can query tables via the normal Postgres protocol and libraries.
-
- Postgres server
- Downloaded and installed when the CLI first runs.
-
- Postgres Foreign Data Wrapper (FDW) extension.
When Steampipe starts the Postgres server, it also installs its FDW. The FDW extension tells the Postgres server which virtual tables it provides. When Postgres computes a query over those tables the FDW extension will resolve the data by making the HTTP API calls.
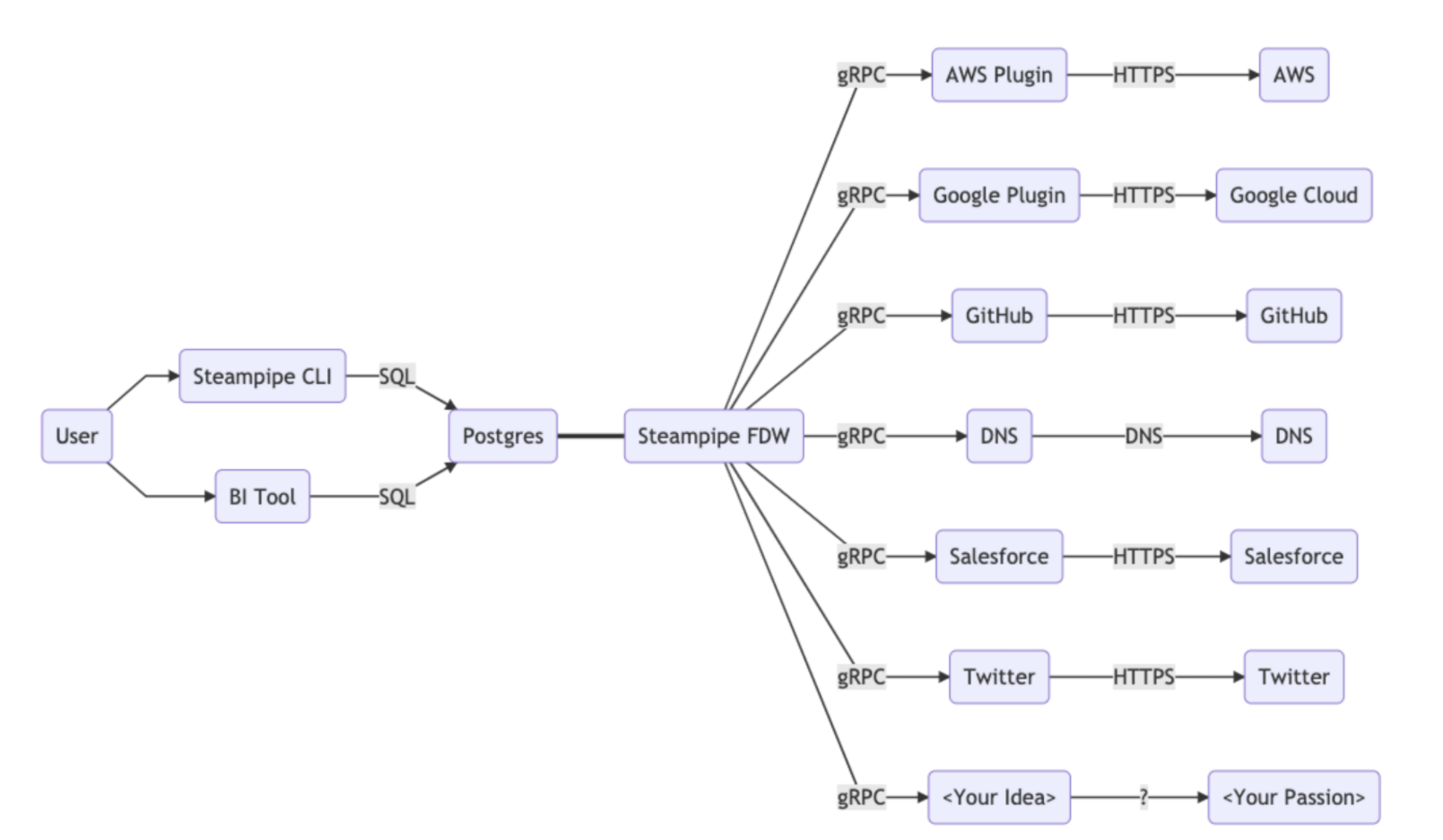 Steampipe Architecture
Steampipe Architecture
Postgres Foreign Data Wrapper extensions fetch the data from remote API's
Why Steampipe is useful
Steampipe is useful for the same reason the tdog CLI is useful:
In short: (tables + query language) > REST because they facilitate fast-feedback-loop interactive exploration by listing and viewing your tables, and by allowing you to use a familiar and optimized query language to construct result sets.
Other advantages:
- Concurrent HTTP requests with a synchronous interface.
- Your code can make a synchronous Postgres query, which under the hood uses maximum concurrency to download all resources, if the underlying API supports it (E.g Listing the same object types from many AWS regions).
- No need to use async-await, threads or message passing in your code.
- Tabular interface.
- Inspect the table schema's instead of the API docs.
- Your code can pipe in data from a Postgres query that is tabular/flattened (instead of JSON or XML where you may need to traverse tree paths to get the scalar value you want). This makes code concise and direct.
The AWS team recommend Steampipe
https://aws.amazon.com/blogs/opensource/querying-aws-at-scale-across-apis-regions-and-accounts/
Rapid acquisition of API-based data is only the start. We think that SQL is the best way to normalize data from diverse APIs, then reason across them. We’ve compiled a rich set of examples to spark your imagination. Now it’s your turn: Show us your own queries!
Issues with Steampipe
-
Hard to observe/understand underlying API calls.
- Because the code is embedded into the Postgres server process, you cannot get the logs of just the extension code in the same way you might redirect stdout of a CLI to your logging server. API specific args will have to be passed through the Steampipe CLI.
- If you are not familiar with the remote API, you will have no idea how your query translates to API calls. E.g. nested sub queries may be making a huge amount of API calls, some of which must be done serially (e.g. pagination).
-
Slow queries.
- A query that makes network requests, and a query that reads data from the Postgres data store are completely different.
- You cannot use indexes with FDW virtual tables.
- Any optimizations the Postgres server can do for regular queries likely do not apply when the data is remote.
- API's may not natively implement
WHEREfilters.- This means the whole data set has to be downloaded even if you want only 5% of the items.
- Local SSD's are around 1000x faster to read from than remote API's. Standard SQL server advice is to make sure your dataset fits inside your RAM for another 1000x speed up compared to SSD reads.
-
Caching may be incorrect
- If the underlying remote API is not events based (which would mean all events can be efficiently applied up to this current moment before the query is run), caching logic will have to determine whether all the objects that are scanned in the query are up to date.
- This could be an issue if your query assumes it is seeing the current state of the world, when it may be reading data from a few minutes ago that was cached. This could lead to incorrect logic.
-
Read transactions are not possible
- Read transactions are useful so that the current process reading from the database can get a "snapshot" of the current state of the world.
- If you are making multiple queries as part of a report, you want those queries to all be consistent with one another (if you had no read-transaction, data inserted between two read queries would modify aggregate totals).
- Even if the FDW extension code was read transaction aware, it still may not be able to provide a real read transaction due to the caching issue above.
- Read transactions are useful so that the current process reading from the database can get a "snapshot" of the current state of the world.
 Local disk vs remote network latency comparison from Latency Numbers Every Programmer Should Know
Local disk vs remote network latency comparison from Latency Numbers Every Programmer Should Know
Advantages of using the tdog CLI over Steampipe
Steampipe has support for Stripe, but it only has 7 tables and will suffer from the above general issues.
The tdog CLI inserts data directly to Postgres native tables, and applies events up to the current moment using Stripes /events endpoint. This avoids the issues listed above.
Try tdog for free against a Stripe test account
Conclusion
Steampipe is especially useful if your code needs to read from the AWS API's, give it a try (after tdog of course).